Enterprise Data Science, Machine Learning, and AI
Top 10 AI Platform Use Cases For the Enterprise

Commercial use at a company of more than 200 employees requires a Business or Enterprise license. See Pricing
Don’t miss out! Get access to: Cloud Notebooks, Anaconda Assistant, easy application deployment, learning resources, and updates from Anaconda.
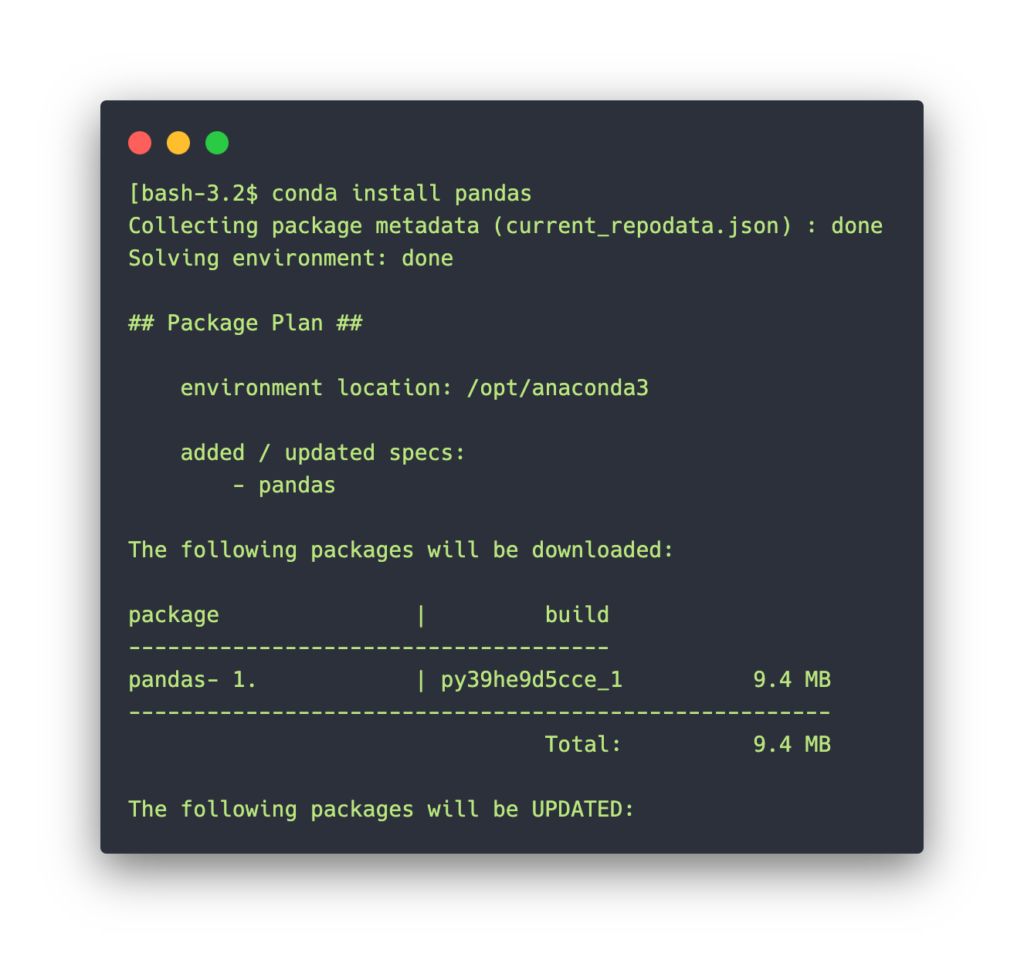
Spend more time developing and less time managing package updates and dependencies

Access the open-source software you need for projects in any field, from data visualization to robotics.

With our intuitive platform, you can easily search and install packages and create, load, and switch between environments.

Our securely hosted packages and artifacts are methodically tested and regularly updated.
Millions of developers and data scientists research, innovate, and discover using Anaconda Distribution

Open-source package and environment management system that runs on Windows, macOS, and Linux. Install, run, and update packages and their dependencies.
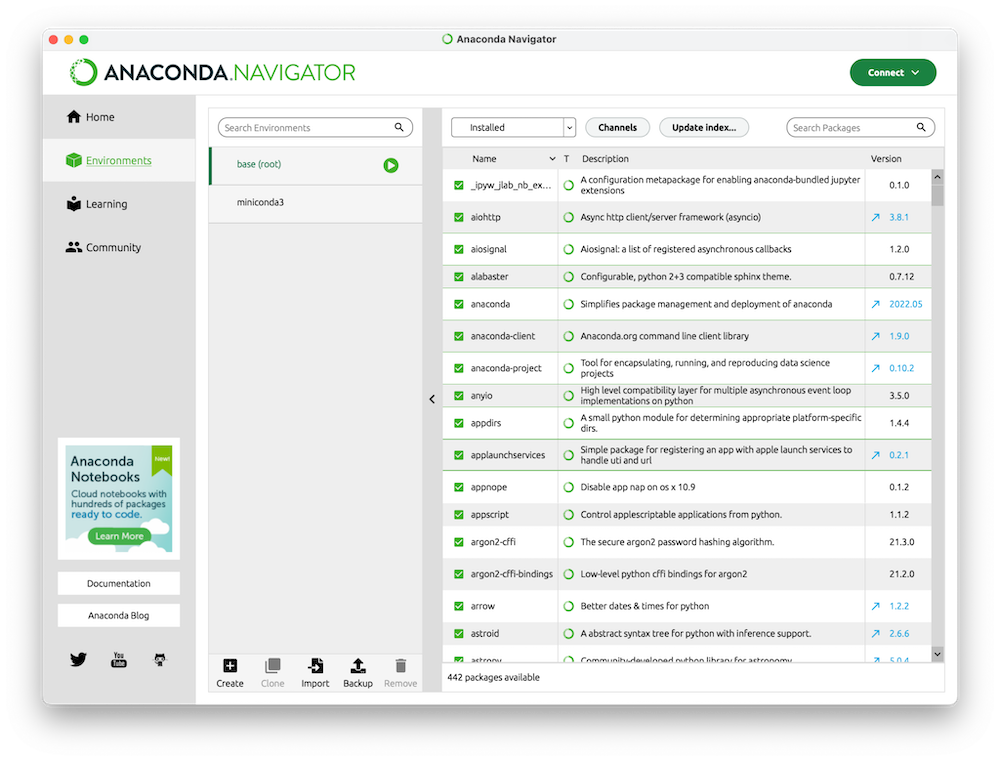
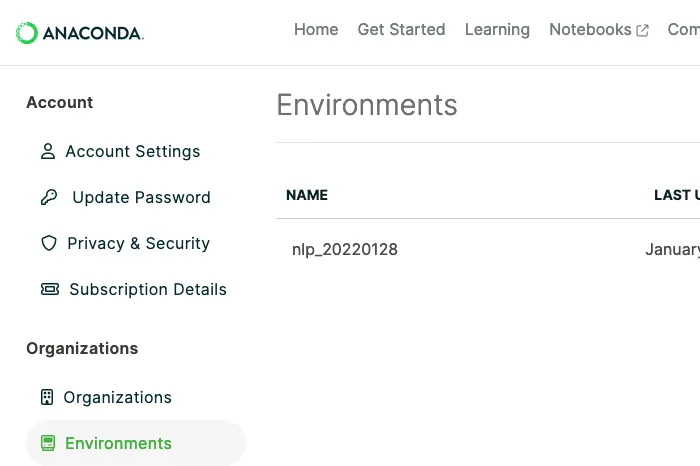
Connect Anaconda Navigator to our community portal, Anaconda Cloud, to securely store your local environments in the cloud.